<정의>
CUDA : Compute Unified Device Architecture
NVCC : NVIDIA CUDA Compiler
< 그래픽카드 계산 능력 (Compute capability)>
- 구조 : X(주 개정 Major).Y(부 개정 Minor)
- compute_XY, sm_XY (Streaming Multiprocessor)하고 넘버링을 같이한다.
- Toolkit은 API라고 생각하면 헷갈리지 않는다.
- 확인 방법 :
- 사이트에서 확인 : developer.nvidia.com/cuda-gpus
- VS로 확인 : Cuda toolkit 설치시 Cuda sample도 같이 설치 했다면, 1_Utilities에 있는 deviceQuery를 실행해본다.
- 관련 링크
- https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/#options-for-steering-gpu-code-generation
<CMD에서 Cuda toolkit version 확인>
CMD에서 nvcc --version을 입력하면 버전을 확인할 수 있다.
단, 환경변수 Path 부분에 Cuda가 설치된 경로가 있어야 한다.
예시 (여기서 v10.1은 설치된 toolkit 버전 정보이다.)
예1) C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin
예2) C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\libnvvp
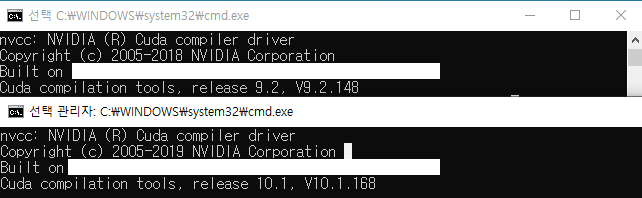
< 스레드 >

-
Grid > Block > Thread
- 2.x 버전 이상에서 3D Grid가 지원된다.
-
GPU에서 각 블록당 최대 스레드 수는 1024개 (물론 이 수치는 그래픽카드나 CUDA 버전마다 다름)
(블록의 모든 스레드는 동일한 프로세스 코어에 상주, 해당 코어의 제한된 메모리 자원 공유) - 스레드 블록은 독립적으로 실행되어야 함.
- 블록 내의 스레드는 일부 공유 메모리를 통해 데이터를 공유하고 실행을 동기화하여 메모리 액세스를 조정함으로써 협력 가능.
(__syncthreads() 함수 등)
<C 런타임>
- cudart : 런타임
- 정적 : cudart.lib / libcudart.a
- 동적 : cudart.dll / libcudart.so - 명시적인 초기화 기능은 없음, 처음 호출 될 때 초기화 됨.
- 초기화 중, 런타임은 시스템의 각 장치에 대한 CUDA context를 만듦. (장치의 primary Context)
< 함수 선언 >
- __global__ : 커널에서 선언된다, 호스트(CPU)에서 호출되고 장치(GPU)에서 실행됨 (함수는 Recursion 지원 불가, 변수 리스트가 일정해야함)
- __device__ : 장치(GPU)에서 선언되는 함수, 호출 및 실행도 장치(GPU)에서 실행 (함수는 Recursion 지원 불가, 변수 리스트가 일정해야함)
- __host__ : 호스트(CPU)에서 선언되는 함수, 호출 및 실행도 호스트(CPU)에서 실행
- __noinline__ : 인라인 금지
- __forceinline__ : 인라인 강제
< 변수 선언 >
- __device__ declares device variable in global memory, accessible from all threads, with lifetime of application
- __constant__ declares device variable in constant memory, accessible from all threads, with lifetime of application
- __shared__ declares device varibale in block's shared memory, accessible from all threads within a block, with lifetime of block
- __restrict__ standard C definition that pointers are not aliased
< 메모리 타입 >
- Private local memory : Thread 내부에서 생성되고 Thread 사이에 공유 불가
- Shared memory : Thread 에서 생성되고 같은 Block에서 공유 가능
- Global memory : 디바이스 전체에서 접근 가능
- Constant memory : Thread 내부에서 읽기 전용으로 접근 가능
- Texture memory : 디바이스 전체에서 접근 가능, text2D 함수로 접근
※ Device memory ≒ Global memory : Cuda 문서에서 중복용어를 사용...
< 벡터 >
데이터 (vector_types.h)
- char1, uchar1, short1, ushort1, int1, uint1, long1, ulong1, float1
char2, uchar2, short2, ushort2, int2, uint2, long2, ulong2, float2
char3, uchar3, short3, ushort3, int3, uint3, long3, ulong3, float3
char4, uchar4, short4, ushort4, int4, uint4, long4, ulong4, float4
longlong1, ulonglong1, double1
longlong2, ulonglong2, double2
longlong3, ulonglong3, double3
longlong4, ulonglong4, double4
- 구조체로 정의 되어 있으며, 접두어인 u는 unsigned (명시되지 않은 것은 signed),
접미어인 숫자는 차원(구조체 내에 변수 개수로 생각해도 된다)이다. - longlong (ulonglong) 의 경우 "long long int" 로 선언되어 있음
- 이들 자료형은 make_<type>(x, ...) 형식으로 생성할 수 있다. (vector_functions.h에 정의 됨)
- 예시) float2 myFloat2 = make_flat2(1.4, 1.7);
- dim3 (vector_types.h)
|
1
2
3
4
5
6
7
8
9
10
11
|
struct __device_builtin__ dim3
{
unsigned int x, y, z;
#if defined(__cplusplus)
__host__ __device__ dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
__host__ __device__ dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
__host__ __device__ operator uint3(void) { uint3 t; t.x = x; t.y = y; t.z = z; return t; }
#endif /* __cplusplus */
};
typedef __device_builtin__ struct dim3 dim3;
|
cs |
- 양의 정수형 인자를 가진 벡터를 정의하는데 사용
- 기본적으로 3개의 인자를 가지지만, 모두 다 사용할 필요는 없다.
- 미리 선언된 벡터 변수 (device_launch_parameters.h에 정의)
- uint3 __device_builtin__ __STORAGE__ threadIdx : 블록 내부에서 스레드 인덱스 (thread index within block),
쓰레드는 1차원, 2차원, 3차원 인덱싱이 가능하다. - uint3 __device_builtin__ __STORAGE__ blockIdx : 그리드 내부에서 블록 인덱스 (block index within grid)
- dim3 __device_builtin__ __STORAGE__ blockDim : 블록 크기, 차원 수 (dimensions of block)
<스레드> 에서 있는 그림을 예로들면 blockDim.x = 4, blockDim.y = 3 - dim3 __device_builtin__ __STORAGE__ gridDim : 커널의 블록 수(dimensions of grid)
<스레드> 에서 있는 그림을 예로들면 gridDim.x = 3, gridDim.y = 2 - int __device_builtin__ __STORAGE__ warpSize : CUDA Instruction이 동시에 처리가능한 CUDA 스레드 (number of threads in warp)
-
인덱싱 (연구가 필요하다...)
-
1차원 (x) : blockDim.x * blockIdx.x + threadIdx.x
-
2차원 (x,y) : blockDim.x * blockIdx.x + threadIdx.x , blockDim.y * blockIdx.y + threadIdx.y
-
2차원 (x) : N x N 의 스레드
-
(N.x * blockDim.y * blockIdx.y) + (N.x * threadIdx.y) + (blockDim.x * blockIdx.x) + blockIdx.x
-
idx_y * N.x + idx_x
-
idx_x = blockDim.x * blockIdx.x + threadIdx.x
-
idx_y = blockDim.y * blockIdx.y + threadIdx.y
-
-
|
1D grid of 1D blocks |
__device__ |
int blockId = blockIdx.x |
|
1D grid of 2D blocks |
__device__ |
int blockId = blockIdx.x |
|
1D grid of 3D blocks |
__device__ |
int blockId = blockIdx.x |
|
2D grid of 1D blocks |
__device__ |
int blockId |
|
2D grid of 2D blocks |
__device__ |
int blockId |
|
2D grid of 3D blocks |
__device__ |
int blockId |
|
3D grid of 1D blocks |
__device__ |
int blockId |
|
3D grid of 2D blocks |
__device__ |
int blockId |
|
3D grid of 3D blocks |
__device__ |
int blockId |
- 참고 링크 (1D 배열 인덱스 변환) : https://cinema4dr12.tistory.com/900
- 인덱싱 공식 :
- 인덱싱 용어 :
<커널 함수 선언>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
__global__ void kenel(...){...}
// 블록 특성
// cuda 1.x has 1D and 2D grids, cuda 2.x adds 3D grids
dim3 blocks( nx, ny, nz );
// 블록 내 스레드 특성
// cuda 1.x has 1D, 2D, and 3D blocks
dim3 threadsPerBlock( mx, my, mz );
//
kernel<<< blocks, threadsPerBlock >>>( ... );
|
cs |
커널 선언시 들어가는 블록, 스레드 크기 관련
(대부분 예제가 이런 형식인데... 규칙이 있는 것인가에 대해서는 찾아보는 중)
|
1
2
3
4
5
6
|
int numElements = 임의 숫자 (보통 길이???);
int threadsPerBlock = 임의 숫자;
int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock
커널함수<<<blocksPerGrid, threadsPerBlock>>>(인자들);
|
cs |
< 행렬 >
CUDA는 열(Column)을 기준으로 행렬을 배치한다. (즉, x = column y = row)
|
(0,0) |
(1,0) |
(2,0) |
(3,0) |
|
(0,1) |
(1,1) |
(2,1) |
(3,1) |
|
(0,2) |
(1,2) |
(2,2) |
(3,2) |
<코드 설계 패턴>
- 호스트 메모리 할당
- 디바이스 메모리 할당
- 호스트 → 디바이스로 데이터 복제
- 디바이스에서 연산
- 디바이스 → 호스트로 데이터 복제
- 결과 가공
- 호스트, 디바이스 메모리 할당 해제
<빌드 과정>
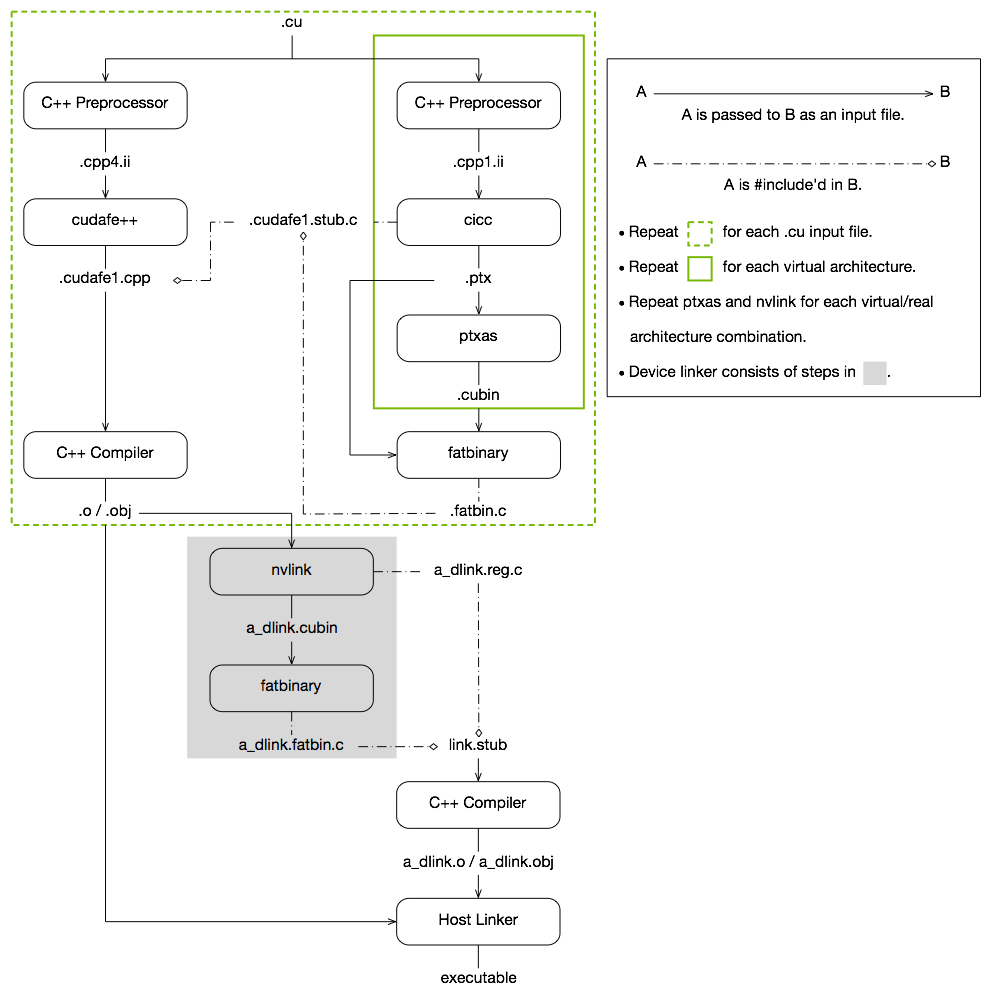
- cubin : CUda BINary
PTX도 포함가능. 아키텍처에 따라서 cubin이 다르기 때문에 다른 장치간 호환에 문제가 있음. - ptx : Plain TeXt
아직 완전히 최적화 되지 않은 중간 어셈블리 언어 (장치마다 레지스터 수가 다르기 때문에). 아키텍처 지정이 가능 sm_xx 또는 compute_xx가 맞으면 호환되는 것 같음.
Debugging 모드 (Debug 정보를 포함할 경우)로 출력한 ptx 파일를 열어보면, 헤더파일을 절대경로로 참조하는 것을 알 수 있다.
- 관련 링크
- Document (CUDA compilation trajectory) : https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html#cuda-compilation-trajectory__cuda-compilation-from-cu-to-executable
- https://stackoverflow.com/questions/7696230/nvidia-nvcc-and-cuda-cubin-vs-ptx
- https://devtalk.nvidia.com/default/topic/504259/cubin-vs-ptx/
- https://stackoverflow.com/questions/37759451/compiling-cuda-ptx-to-binary-for-an-older-target
< Visual studio 2017에서 Cuda 10 프로젝트 생성시 나오는 샘플 코드 >
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
|
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
|
cs |
<문제점 해결>
환경변수 확인)
하나의 PC에 여러 버전의 CUDA를 사용하는 경우 주의해야할 사항.
환경 변수 값이 안 맞으면 제대로 실행되지 않는 경우가 존재한다.
※ Rapid Environment Editor 라는 프로그램이 있는데, 환경변수를 편집을 하는 프로그램이다.
덤으로 환경변수가 잘못된 경로를 가지는 경우. 빨간 글씨로 표시도 해준다.
https://www.rapidee.com/en/download
Download - Rapid Environment Editor
www.rapidee.com
호환성 확인)
VS2017과 CUDA 9.2 (또는 그 상위버전)에 호환성 문제가 있다고 함.
해결 방법 1) host_config.h 파일에서 _MSC_VER > 1915로 변경
해결 방법 2) 프로젝트 속성 페이지에서 플랫폼 도구 집합을 낮춘다. (v140, 즉 VS2015버전으로 설정)
(관련 링크)
https://www.sysnet.pe.kr/Default.aspx?mode=2&sub=0&detail=1&pageno=0&wid=11470&rssMode=1&wtype=0
※ 예전에 인계받은 CUDA 프로젝트(VS2015에서 편집)가 VS2017에서 구동이 안되는 문제가 있었다 (CUDA로 처리하는 영상이 뜨지 않음). 플랫폼 버전 (SDK버전)은 최신으로 써도 되는데, v141(VS2017)로 마이그레이션하지말고, v140(VS2015)를 유지하는 것이 좋다. (아니면 host_config.h 파일을 수정해도 될듯?)
빌드 문제)
빌드할 때, 변경된 cu파일을 감지하지 못하는 이슈가 존재하는데,
(본인의 경우에는 ptx로 출력하는 프로젝트가 cu파일이 변경되었음에도 불구하고, Rebuild를 하지 않는 문제가 있었음)
현재(19.12.18.)까지도 해결되지 않은듯 하다. (NVidia 포럼 링크)
수동으로 프로젝트나 솔루션을 다시 빌드 해야하는 수고가 동반된다.
< 기타 참고한 링크 >
- Document : https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
- Syntex : http://www.icl.utk.edu/~mgates3/docs/cuda.html (CC License : CC-BY / CC - BY -SA)
- dim3 : https://codeyarns.com/2011/02/16/cuda-dim3/
- http://haanjack.github.io/cuda/2016/03/27/cuda-prog-model.html
- https://www.slideshare.net/EdisonLee1/cuda-moducon2018
- http://www.miruware.com/goods/cuda_detail.asp?scate=59
- Matrix multiple : https://takehoon.tistory.com/entry/CUDA-index-%EA%B7%B8%EB%A6%BC
'Study > CUDA' 카테고리의 다른 글
| CUDA를 C++/CLI로 만들어보자 (0) | 2020.02.04 |
|---|---|
| CUDA를 C#에서 사용해보자 (2) | 2019.07.08 |